Le cercle de la modélisation
Marcello Vitali Rosati,
« Le cercle de la modélisation »,
C’est la matière qui
pense (édition augmentée), Presses universitaires de Rouen et du
Havre, Mont-Saint-Aignan, 2025, ISBN : 979-10-240-1912-3, https://ceen.univ-rouen.fr/matiere-marcello/chapitre5.html.
version 1, 18/06/2025
Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA
4.0)
Le rapport entre théorie du texte et incarnation matérielle du texte en un document peut être pensé comme un cas de modélisation. En suivant la suggestion de Jean-Guy Meunier (2014, 2017), nous pouvons donc identifier trois étapes de la modélisation : un modèle théorique, un modèle formel et un modèle matériel. Selon cette approche, il y aurait d’abord une description théorique du texte, faite en langage naturel ; ensuite une formalisation de cette description en un langage non ambigu – formel justement ; et pour finir une implémentation matérielle du modèle formel.
Cette schématisation est proposée par Meunier – en se basant notamment sur les travaux de Willard McCarty (2014) – spécifiquement pour l’implémentation numérique de modèles. Le modèle formel, dans le cas spécifique d’une modélisation qui a comme but de produire une implémentation matérielle en informatique, est un modèle numérique, dans le sens qu’il est mathématique et fonctionnel. Le modèle formel, en d’autres termes, consiste à transformer le modèle théorique en une série d’entités discrètes et atomiques reliées entre elles par des fonctions calculables. Or il me semble que l’on peut garder cette description de la modélisation au-delà des implémentations informatiques : aussi quand le modèle matériel vise d’autres supports – notamment le papier.
Reprenons notre exemple précédent pour mieux expliquer cette idée. Selon le schéma de Meunier, il y aurait d’abord un modèle théoriqueElena Pierazzo se refère à cette première modélisation en l’appelant tout simplement « théorie » du texte. Voir Pierazzo (2016), p. 37 et suiv.↩︎. Dans notre premier exemple : ce texte est un distique élégiaque en grec, composé de deux vers, un hexamètre et un pentamètre.
Ce modèle théorique doit ensuite être converti en modèle formel. Dans le cadre d’un modèle formel destiné à une implémentation informatique, il faudra transformer les affirmations précédentes en unités discrètes et atomiques reliées par des fonctions. Donc par exemple : on décrira comme unité, le caractère grec, le vers, le pied, la langue et on aura ensuite des relations qui définissent les interactions possibles parmi ces unités. Cela nous permettra ensuite d’implémenter ce modèle fonctionnel en un modèle matériel.
Mais on pourrait également imaginer un modèle formel dont
l’objectif est d’être implémenté dans un modèle matériel papier. Il
faudra, dans ce cas aussi, expliciter de façon formelle le modèle
théorique. On n’aura pas besoin de fonctions, mais toujours de
définitions non ambigües pour chaque élément utilisé. Par exemple : un
vers est une série de mots isolés dans une ligne. Un mot est une série
de caractères dont la combinaison produit un sensLa question de savoir ce qu’est un mot n’est bien sûr
ni neutre ni anodine. Les approches promues par les modèles inductifs
récents sont basées sur la reconstruction d’un dictionnaire à partir
de l’analyse statistique de patterns récurrents. C’est le
principe du byte pair encoding. Évidemment, on pourrait se
baser à l’inverse sur un système expert et commencer par une liste de
mots établie a priori (un dictionnaire de la langue). L’approche
inductive peut par ailleurs avoir l’avantage de faire apparaître des
« structures ». Voir sur ce sujet les travaux de Juan Luis Gastaldi
(2024).↩︎.
On en arrive au modèle matériel qui consiste en la manifestation
physique du texte. Notre épigramme sera donc quelque chose : un
fichier .txt par exemple, ou un fichier
.tex, ou un fichier XML-TEI,
ou un texte imprimé d’une certaine manière, avec une mise en page
spécifique.
Or cette description de la modélisation en trois étapes est sans doute utile pour comprendre les différents aspects impliqués dans les modèles, mais elle ne correspond pas à la réalité. En effet, aucun des modèles théorique, formel ou matériel ne peut exister en tant que tel ; ils existent seulement ensemble.
Un texte n’existe que dans sa matérialité située et c’est sa matière qui contient le sens du texte formellement structuré. Les trois modèles n’en font en réalité qu’un. Encore une fois, l’idée selon laquelle la pensée se ferait « avant » l’incarnation est complètement fausse. Cette idée, pourtant, est très courante et très présente dans le monde de la recherche en sciences humaines. Le grand chercheur imagine le modèle théorique, fait à la limite une première ébauche du modèle formel et laisse ensuite le travail « trivial » aux bras, aux mains sales qui toucheront la matière. Mais la pensée est dans la matière et la conviction du grand chercheur cache en réalité non pas une grande idée théorique que les petites mainsLe concept de « petites mains » et la mise en question de cette pyramide de valeurs ont été thématisés par Margot Mellet, en particulier dans trois de ses textes (2021, 2023, 2024).↩︎ auront ensuite du mal à implémenter, mais juste une idée floue – quand il y en a une – car ancrée sur une matérialité pauvre et mal comprise, une idée vague qui devra ensuite être précisée par les petites mains en question qui feront, elles, le travail de théorisation – dont le chercheur prendra à la fin le mérite, si c’est une réussite, ou pour lequel il blâmera les petites mains, si c’est un échec.
Il n’y a pas de sens en dehors de la matière. Encore une fois : c’est la matière qui pense.
La théorie se développe en manipulant la matière ; le modèle théorique émerge lorsqu’on se heurte à une balise que l’on ne peut pas imbriquer, à un format qui exprime un concept particulier d’une manière spécifique et qui révèle ainsi l’incompatibilité logique et formelle entre deux visions du texte, à la disposition des lignes dans une page et des mots dans une ligne pour éviter une veuve ou une orpheline, à la facture d’une police de caractères qui ne permet pas de voir la différence entre un esprit et un accent (en grec).
Un modèle théorique riche est celui qui émerge d’une longue manipulation. C’est la manipulation de la matière textuelle – qu’elle soit numérique ou papier – qui fait voir les différents détails, les cas particuliers, les exceptions, les incompatibilités, les contradictions, les implications profondes. C’est cette manipulation qui précise le modèle formel en délinéant les unités atomiques et les relations qui les lient. Un modèle théorique qui ne passe pas par la matière est en réalité un modèle théorique qui émerge d’une manipulation paresseuse et trop rapide. La théorie abstraite est juste une théorie très pauvre. Et pourtant, combien de fois entend-on des phrases comme : « moi, je m’occupe de la partie intellectuelle, le reste je l’ai laissé à l’ingénieur ». Voilà, cette « partie intellectuelle » est simplement une manipulation paresseuse qui produit une théorie vague, une pensée simpliste qui sera ensuite complexifiée, étoffée, enrichie par l’ingénieur qui fera le vrai travail théorique, celui qui consiste à laisser parler la matière pour essayer de comprendre comment elle pense.
Cette affirmation est difficile à démontrer et elle est surtout très difficile à expliquer à ceux et celles qui n’ont jamais fait ce type de travail. Mais elle apparaîtra comme évidente pour « les petites mains ».
Un exemple pourra aider à mieux saisir ce que j’essaie d’exprimer. L’histoire de la création du PressoirVoir Fauchié et al. (2023). Le Pressoir est par ailleurs utilisé pour produire ce livre et les livres de la collection « De code et de plomb » qui l’accueille.↩︎ au sein de la Chaire de recherche sur les écritures numériques à l’Université de Montréal. Le Pressoir est un générateur de sites statiques pensé pour produire des livres savants augmentés – surtout en sciences humaines.
L’histoire commence en 2013, justement, avec une idée vague et un projet de collection aux Presses de l’Université de Montréal : la collection « Parcours numériques » proposée par Michael Sinatra et moi-même. L’idée vague, ou pour employer la terminologie utilisée ici, le modèle théorique initial, est d’avoir une collection avec une double version : papier et numérique. La problématique qui nous animait était de comprendre les relations possibles entre édition numérique et édition papier. Nous essayions de comprendre quel allait être le futur du livreVoir « Le futur du livre » : https://blog.sens-public.org/marcellovitalirosati/le-futur-du-livre/.↩︎ à une époque où la discussion était particulièrement polarisée : d’une part, les « progressistes » qui envisageaient un « passage » total au numérique, en considérant les environnements numériques comme « meilleurs », plus expressifs et plus puissants et, de l’autre, les « réactionnaires » qui faisaient l’éloge du papier en voyant dans le numérique un appauvrissement ou du moins une menace pour la riche tradition du papier.
L’intuition à la base de notre démarche était d’imaginer au contraire une complémentarité entre les deux modèles en essayant d’identifier les caractéristiques, les forces et les faiblesses de l’un et de l’autre, et en les mettant en dialogue au lieu de les mettre en compétition. Le papier devait épouser une des caractéristiques que le support semble mieux implémenter, à savoir la linéarité.
Comme le remarque notamment Christian Vandendorpe
(1999),
différents supports sont caractérisés par un niveau différent de
linéarité. À partir d’un support très linéaire, comme le papyrus, fait
pour être déroulé en rendant très peu ergonomique un aller-retour
entre diverses parties du texte, en passant par le codex, dont la
structure en pages avec une numérotation permet une certaine
indexation – une table des matières et des index qui rendent possible
de sauter d’un passage à l’autre –, jusqu’à l’hypertexte qui est pensé
– à partir d’intuitions comme celle du memex de Vannevar BushBush
(1945), Nelson (1965) et Mille (2014)
pour une histoire du memex et de son rapport avec le web.↩︎ – pour permettre une tabularité
très poussée. L’« intertextualité », si on veut l’appeler ainsi, des
hypertextes est loin d’être une idée abstraite et vague de « liens »
entre les textes, elle est matérielle, elle est faite d’hyperliens qui
permettent concrètement de transformer des passages de texte ou des
mots en unités atomiques auxquelles le lien peut se référer. Cette
matérialité peut déjà être identifiée dans les premières idées de
Bush, qui
propose la notion de lien à partir des possibilités techniques qu’il
connaissait en 1945 : des microfilms, lus par une machine, avec la
possibilité mécanique d’enregistrer une position spécifique du lecteur
pour pouvoir ensuite la rappeler. Cette idée matérielle
changera ensuite de forme ; en HTML,
une balise – un <span>texte</span> – peut
avoir un identifiant qui est exprimé en tant qu’attribut – par
exemple, <span id="1">texte</span> auquel le
lien peut se référer – avec une syntaxe du type
<a href="#1">texte du lien</a>. Une référence
de ce type est matériellement impossible dans un support papier – du
moins dans les syntaxes normalement utilisées. Un index peut se
référer à une page, mais non à un mot.
À partir de ce constat – loin d’être désincarné, même s’il se fonde sur une manipulation textuelle très superficielle, qui ne rentre pas dans les milliers de détails possibles, mais qui se limite à regarder la matérialité d’une des macrostructures du format HTML et du format « livre papier » –, l’idée de « Parcours numériques » était d’avoir, pour chaque livre, une version linéaire et une version tabulaire. La version linéaire devait essayer de radicaliser l’idée de linéarité : le papier n’aurait pas contenu toutes les structures tabulaires qu’il contient normalement, comme les notes de bas de page, les références bibliographiques et l’appareil critique en général, justement parce que ces structures sont peu adaptées au support. La version numérique, au contraire, devait radicaliser l’idée de tabularité en multipliant les renvois infratextuels, l’ajout d’appareil critique, la mise à disposition de parcours de lecture alternatifs.
Le pari était de proposer non pas deux versions alternatives, mais deux versions complémentaires, permettant une double lecture. Une qui permette de saisir la thèse du livre en suivant une argumentation linéaire – comme un roman – et l’autre qui suggère une lecture d’étude et d’approfondissement d’un sujet, en laissant les thèses et l’argumentation du livre sur le fond.
Exemple de livre au sein de la collection « Parcours Numériques »
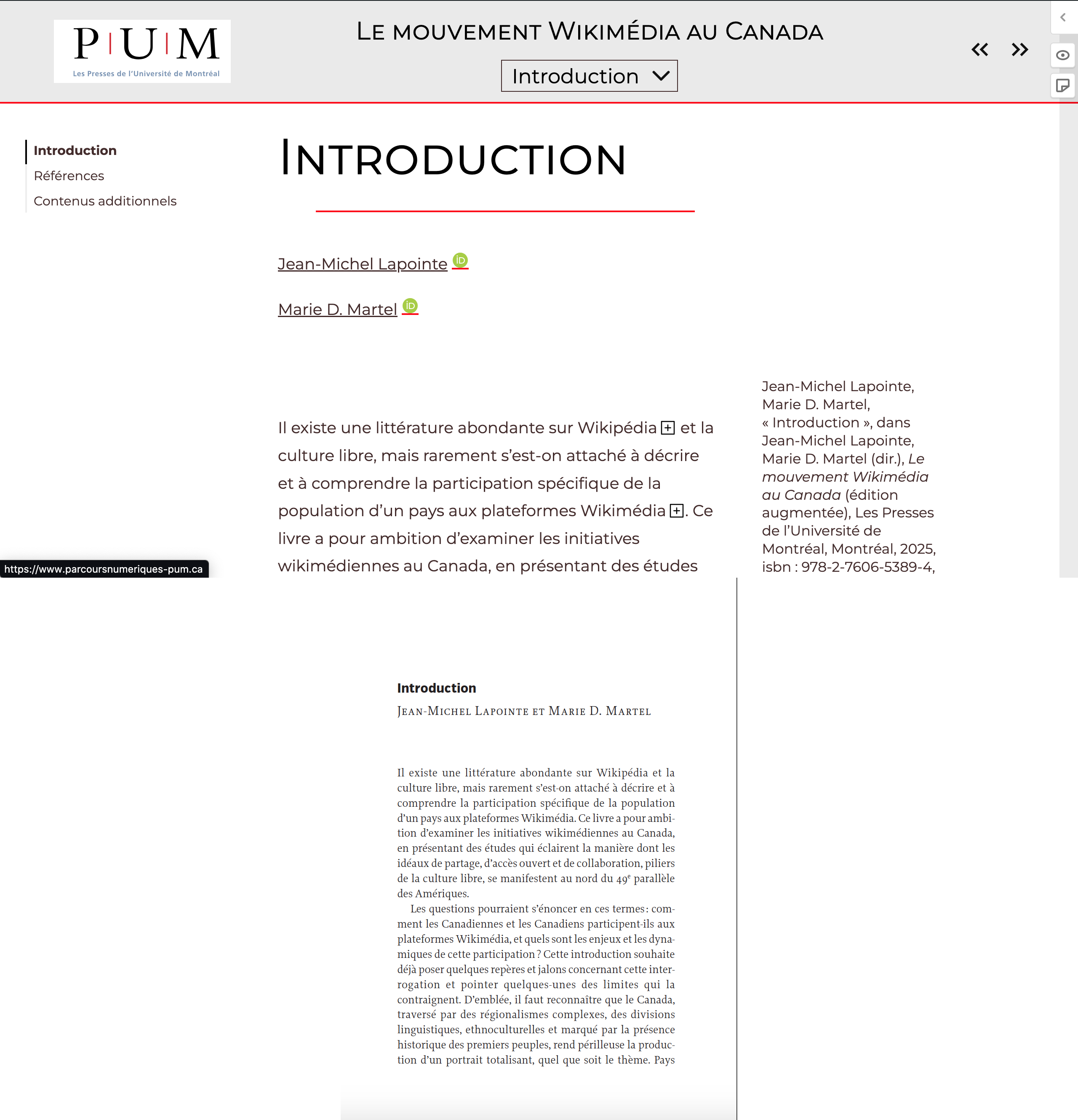
Dans la collection « Parcours Numériques » des Presses de l’Université de Montréal, nous publions les livres en accès libre aussi bien dans leurs versions web (partie supérieure de l’image) que dans leurs versions PDF (partie inférieure de l’image), permettant deux modes de lecture différents – et complémentaires ? – des ouvrages.
Mais ces deux modèles théoriques du texte, justement parce que basés sur une analyse légère des modèles matériels, restaient très pauvres. L’idée a commencé à se préciser lors des premières implémentations – pour la version numérique, la construction d’une plateforme réalisée avec le CMS Spip par Aurélie Veyron-ChurletNous avions considéré d’autres possibilités, dont Scalar, une plateforme créée dans le but de produire des livres augmentés. Mais les contraintes des autres plateformes s’adaptaient mal à notre idée initiale et la possibilité de personnaliser Spip avait semblé nous donner plus de liberté.↩︎ ; pour la version papier, la réalisation des premiers livres, leur mise en page, le travail avec les auteurs pour imaginer avec eux un texte savant sans appareil critique.
Concentrons-nous sur la version numérique. L’usage de Spip était une manière de déléguer le modèle théorique aux possibilités d’implémentation proposées par ce CMSCMS – évidemment avec un travail d’adaptation. Spip fonctionne avec une base de données relationnelle assez classique, sur le principe de la plupart des CMS des années 2000. Le balisage infratextuel est assez limité, car justement l’implémentation en base de données relationnelle n’est pas compatible avec la structure à arbre typique, par exemple, d’un document XML.
La collection a vu le jour et les premiers livres ont été publiés en 2014. En éditant les textes augmentés, en collaboration avec Hélène Beauchef, l’éditrice qui s’occupe de la version numérique, nous avons vite réalisé que le modèle théorique que Spip nous proposait était trop pauvre : nous nous sommes heurtés aux caractéristiques figés du modèle matériel que nous avions adopté. C’est là que nous avons réalisé que la seule manière de développer un modèle théorique riche pour un « livre augmenté » était de commencer à toucher à la matérialité du texte, à bricoler, à mettre, donc, la main à la pâte.
En même temps, nous avons lancé un projet éditorial parallèle, les « Ateliers de [sens public] » avec une idée semblable qui aurait pu ensuite être mutualisée pour la collection des « Ateliers » et pour celle de « Parcours numériques ». Le travail, initié avec Hélène Beauchef, Servanne Monjour et Nicolas Sauret, a débuté en repartant d’un balisage textuel flexible, qui nous permettait, au fur et à mesure, de spécifier les structures formelles dont nous avions besoin. Le choix des formats Markdown (pour le texte), YAML (pour les métadonnées) et BibTeX (pour la bibliographie) a semblé une bonne piste. La combinaison de ces trois formats est largement utilisée en sciences humaines, en particulier par une large communauté qui s’est créée autour du convertisseur Pandoc. Il est intéressant de remarquer que Pandoc a été créé par John McFarlane, un philosophe qui l’a précisément développé pour répondre à ses propres besoins de gestion du texte, des besoins proches des nôtres, nous qui voulions justement modéliser des textes en sciences humaines.
Markdown
a donc été utilisé avec l’idée de se servir de Pandoc comme
convertisseur pour produire du HTML.
La syntaxe Markdown
est ainsi employée dans sa version pandoc flavored. Cela
permet notamment de créer des classes ad hoc pour baliser des
contenus, classes qui sont ensuite transformées en classes HTML.
YAML
permet de créer des métadonnées qui s’expriment avec une structure de
type clé-valeur – par exemple titre: Texte du titre.
C’est une syntaxe très légère, excellente pour la modélisation, car on
peut créer n’importe quel jeu de métadonnées tout simplement en
écrivant du plein texte. S’il est besoin d’une clé de plus, on n’a
qu’à l’ajouter.
Nous avons pu commencer à préciser notre modèle théorique en définissant dans le texte des structures qui devaient être indexées, en produisant des modèles formels pour définir les « contenus additionnels », etc.
Notre possibilité de modélisation était fortement liée à nos
connaissances informatiques : nous n’arrivions à imaginer que les
possibilités que nous étions concrètement capables d’implémenter. Au
début, notre littératie était assez limitée. Nous avons commencé avec
des scripts Bash
qui mettaient ensemble une série de logiciels de bas niveau, comme
awk, sed ou un préprocesseur comme PPhttps://github.com/CDSoft/pp.↩︎ qui permettait d’appliquer
certaines macros à la syntaxe du Markdown,
ainsi qu’un gabarit de mise en forme, créé par Edward Tufte et
implémenté par Dave LiepmannVoir https://www.daveliepmann.com.↩︎.
Notre idée de ce que devait être le texte augmenté et notre modèle théorique étaient directement issus de la matérialité de ces formats et logiciels, et ils évoluaient au fur et à mesure que nos compétences de manipulation augmentaient.
Finalement, le script Bash a été transformé en un script Python, bien plus complexe. Un développeur, David Larlet, a rejoint l’équipe, ainsi qu’un certain nombre de doctorants – parmi lesquels Antoine Fauchié et Roch Delannay. Les capacités de manipulation et l’expérience de traitement d’un nombre de publications croissant nous a permis, à chaque itération, de complexifier le modèle, jusqu’à arriver à un livre augmenté qui pouvait être considéré comme généralisable. Ce n’était plus le modèle qui pouvait fonctionner pour le cas particulier de livre que nous étions en train de publier, mais un modèle théorique qui pouvait décrire une série assez large de livres augmentés. Un modèle théorique qui pouvait donc être partagé, car il décrivait un artefact bien spécifié, formalisé, à la structure claire et réutilisable.
Le Pressoir – Documentation du projet
La documentation du Pressoir, qui en explicite le modèle théorique et en formalise les spécificités textuelles.
Crédits : Hélène Beauchef, Roch Delannay, Antoine Fauchié, David Larlet, Margot Mellet, Servanne Monjour, Nicolas Sauret, Michael Sinatra, Marcello Vitali-Rosati
Qui a conçu ce modèle théorique ? Qui a produit le sens ? Qui a pensé ? Cette idée a émergé dans le travail collectif de manipulation de formats, outils, langages de programmation, textes numériques particuliers, protocoles de versionnage, algorithmes, etc. Ce qui est à l’origine de l’émergence du modèle théorique n’est pas une personne, mais une série de dynamiques complexes qui comprennent des échanges, des formations, la prise en main d’outils et d’environnements numériques particuliers, la collaboration au sein d’un laboratoire dans lequel joue aussi un rôle fondamental la matérialité de l’institution, avec ses spécificités, ses lieux, ses caractéristiques économiques, culturelles, techniques, etc.Mellet parle du café, par exemple : https://blank.blue/conf/crihn/.↩︎ La théorie n’est pas venue d’un individu qui pense, mais elle a émergé des caractéristiques physiques de la matière. Encore une fois : c’est la matière qui pense.
Accepter l’impossibilité de séparer les trois étapes de la modélisation et surtout d’imaginer une hiérarchie qui mettrait le modèle théorique au-dessus – du point de vue de sa valeur symbolique – du modèle formel et du modèle matériel a trois conséquences majeures, deux qui concernent spécifiquement la théorie du texte et la théorie de l’édition, et une dernière qui a une portée plus large que l’on peut facilement caractériser de métaphysique.
En premier lieu, comme nous l’avons vu, il n’est pas possible d’imaginer la réduction de la multiplicité des modèles à une unité. Dit autrement, il n’est pas possible de se poser, avec DeRose et al. (1990), la question What is text, really ? Ce fameux article de 1990 a été l’un des points de départ du XML, en proposant l’idée du texte comme Ordered Hierarchy of Content Objects (OHCO). Or, si cette idée et son implémentation dans les différents langages XML sont sans doute une interprétation très riche de ce que peut être un texte et si cette même idée répond à des besoins herméneutiques communs à plusieurs approches de lecture en sciences humaines, elle ne peut pas être considérée comme la seule possible ni la meilleure. Elle est, elle aussi, située et contextuelle. Comme nous l’avons montré, certaines conceptions du texte ne peuvent y être réduites.
Une deuxième conséquence de nos considérations peut être aussi
comprise comme une critique de l’approche de De Rose et, plus
précisément, de l’idée qu’il est nécessaire, pour produire un modèle
théorique riche du texte, de séparer sa structure sémantique de ses
caractéristiques présentationnelles. Selon cette idée, la force des
approches OHCO serait le fait de se concentrer sur le sens du
texte et d’ignorer l’incarnation matérielle de ce sens dans une forme
particulière. C’est l’idée notamment de séparer de manière nette le
balisage sémantique du traitement présentationnelCette possibilité peut évidemment être questionnée :
c’est ce que fait Christophe Schuwey dans son livre
Interfaces (2019) où on se concentre
sur la façon dont les dispositifs qui permettent l’interaction
matérielle avec le texte affectent son sens. C’est aussi la question
que pose Elena Pierazzo en réfléchissant sur les limitations du modèle
OHCO (2016,
p. 61 et suiv.).↩︎. D’un côté des balises qui
expriment ce que le texte signifie, de l’autre un dispositif qui
permet de « rendre » ce sens avec une incarnation graphique. Pour
donner un exemple : on peut exprimer qu’une série de caractères
constitue un titre de niveau 1 – par exemple, avec la balise HTML
<h1> – et ensuite traiter cette information
de manière graphique ailleurs – par exemple, dans un fichier CSS
qui nous dira qu’il faut mettre ce titre en gras et dans une police de
caractère plus grande. Cette approche est sans doute d’un grand
intérêt. Elle est une bonne modélisation. Comme tous les
modèles, elle permet de délimiter et définir précisément le geste
d’interprétation en incluant certains aspects et en en excluant
d’autres. Mais elle n’est pas la seule légitime. Il serait en effet
tout aussi légitime de se concentrer sur l’aspect graphique comme
aspect signifiant. C’est ce qui arrive, par exemple, lorsqu’on réalise
une édition diplomatique. Cela est évidemment possible en restant dans
une approche OHCO, et il y a notamment des spécifications de schémas
XML
qui se concentrent sur ces aspects. Toutefois, et c’est le plus
important, il ne faut pas se leurrer et croire que la séparation du
balisage en sémantique et présentationnel corresponde à une véritable
séparation d’un sens immatériel par rapport à une incarnation
matérielle de ce sens en un rendu quelconque. Car le balisage
sémantique est lui aussi une incarnation située et présentationnelle
du texte. Lorsqu’on manipule les balises, de fait, on manipule un
artefact matériel, avec une syntaxe spécifique, avec des mises en
forme de cette syntaxe qui souvent ne sont que présentationnelles –
que l’on pense à l’indentation, par exemple, sans laquelle la syntaxe
XML
n’aurait aucun sens, du moins pour une personne qui essayerait de la
produire ou de la lire.
Même l’approche OHCO est donc fortement matérielle. Il ne s’agit pas d’une structure abstraite. Pour être plus précis : le sens du mot « abstraction » est toujours relatif. Faire abstraction signifie mettre entre parenthèses un aspect que l’on ne veut pas considérer, justement pour pouvoir se concentrer sur la manipulation des autres aspects matériels qui nous intéressent et qui risqueraient de rendre trop complexe notre manipulation du texte. L’abstraction, loin d’être une tentative de saisir l’immatérialité, est un effort qui permet d’accroître la matérialité des éléments sur lesquels on se concentre en rendant possible le fait que leur matérialité se révèle de manière encore plus forteUne idée semblable est formulée par Matteo Pasquinelli qui affirme (2023, p. 38) : « Abstraction always operates within given material constraints and through them » (L’abstraction opère toujours à l’intérieur de contraintes matérielles données et à travers elles ; ma traduction).↩︎.